RepMLPNet¶
Introduction¶
Compared to convolutional layers, fully-connected (FC) layers are better at modeling the long-range dependencies but worse at capturing the local patterns, hence usually less favored for image recognition. In this paper, the authors propose a methodology, Locality Injection, to incorporate local priors into an FC layer via merging the trained parameters of a parallel conv kernel into the FC kernel. Locality Injection can be viewed as a novel Structural Re-parameterization method since it equivalently converts the structures via transforming the parameters. Based on that, the authors propose a multi-layer-perceptron (MLP) block named RepMLP Block, which uses three FC layers to extract features, and a novel architecture named RepMLPNet. The hierarchical design distinguishes RepMLPNet from the other concurrently proposed vision MLPs. As it produces feature maps of different levels, it qualifies as a backbone model for downstream tasks like semantic segmentation. Their results reveal that 1) Locality Injection is a general methodology for MLP models; 2) RepMLPNet has favorable accuracy-efficiency trade-off compared to the other MLPs; 3) RepMLPNet is the first MLP that seamlessly transfer to Cityscapes semantic segmentation.
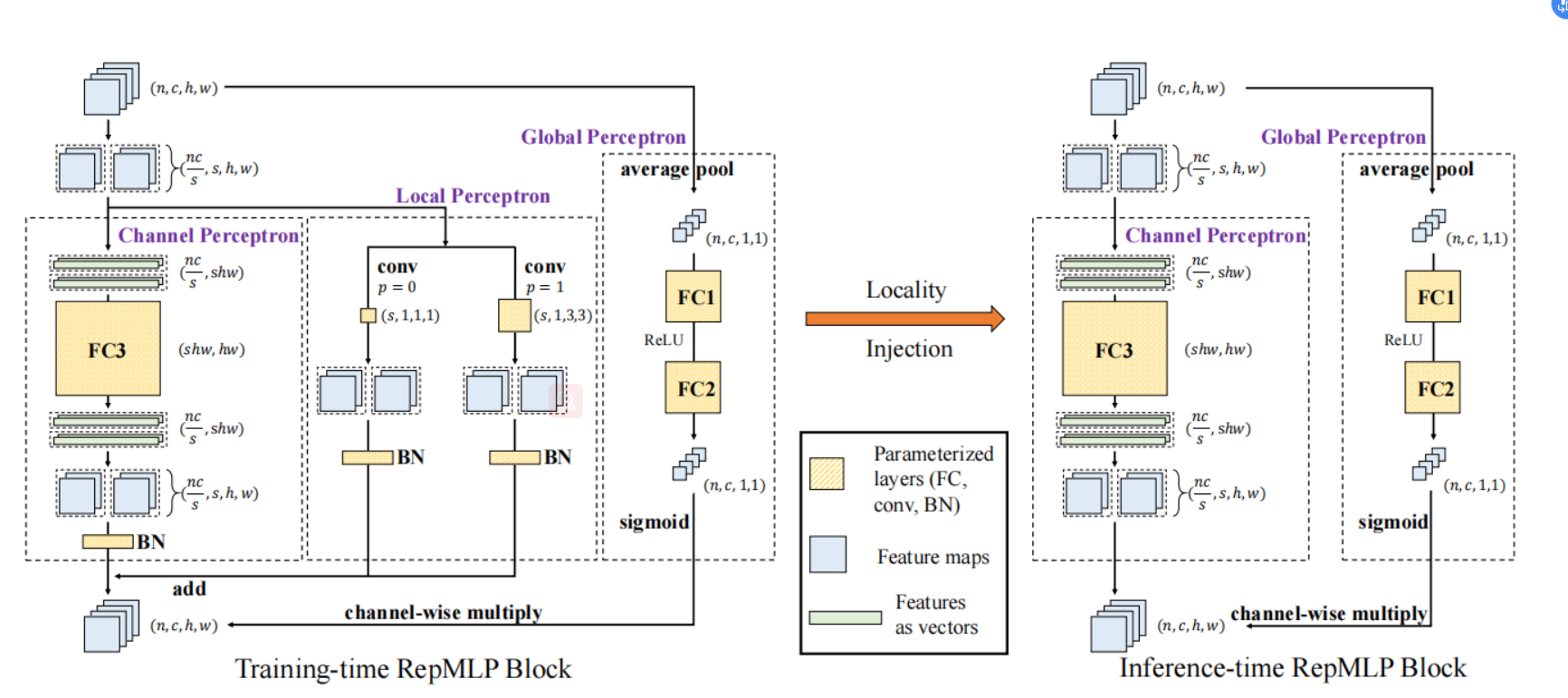 Figure 1. RepMLP Block.[1]
Figure 1. RepMLP Block.[1]
Results¶
Our reproduced model performance on ImageNet-1K is reported as follows.
| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Download |
|---|---|---|---|---|---|---|
| repmlp_t224 | D910x8-G | 76.68 | 93.30 | 38.30 | yaml | weights |
Notes¶
Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
Quick Start¶
Preparation¶
Installation¶
Please refer to the installation instruction in MindCV.
Dataset Preparation¶
Please download the ImageNet-1K dataset for model training and validation.
Training¶
Distributed Training
It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
# distributed training on multiple GPU/Ascend devices
mpirun -n 8 python train.py --config configs/repmlp/repmlp_t224_ascend.yaml --data_dir /path/to/imagenet
If the script is executed by the root user, the
--allow-run-as-rootparameter must be added tompirun.
Similarly, you can train the model on multiple GPU devices with the above mpirun command.
For detailed illustration of all hyper-parameters, please refer to config.py.
Note: As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
Standalone Training
If you want to train or finetune the model on a smaller dataset without distributed training, please run:
# standalone training on a CPU/GPU/Ascend device
python train.py --config configs/repmlp/repmlp_t224_ascend.yaml --data_dir /path/to/imagenet --distribute False
Validation¶
To validate the accuracy of the trained model, you can use validate.py and parse the checkpoint path with --ckpt_path.
python validate.py --model=RepMLPNet_T224 --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
Deployment¶
To deploy online inference services with the trained model efficiently, please refer to the deployment tutorial.
References¶
[1]. Ding X, Chen H, Zhang X, et al. Repmlpnet: Hierarchical vision mlp with re-parameterized locality[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 578-587.